☰
×
Raspagem da web
Navegação na Web
jsoup
Jsoup é uma biblioteca Java usada para analisar e manipular documentos HTML. Ele fornece uma API fácil de usar para extrair e modificar dados de HTML.
Norconex
O Norconex Web Crawler é uma ferramenta de código aberto para rastreamento da Web e extração de dados, usada para coletar dados de sites para análise e insights de negócios.
Guzzle
Guzzle é uma biblioteca cliente PHP HTTP que simplifica o envio de solicitações para sites e APIs, fornecendo recursos fáceis de usar para tarefas de raspagem na web.
Apache Nutch
O Apache Nutch é um rastreador da web de código aberto e um software de mecanismo de pesquisa que permite o rastreamento e a indexação de grandes volumes de conteúdo da web.
Ayakashi.io
Ayakashi.io é uma estrutura de raspagem da web construída em Node.js, apresentando uma automação de navegador sem cabeça, páginas da web dinâmicas e raspagem de aplicativos de página única.
Crawlee
Crawlee permite que você rastreie e rastreie sites. Simultaneidade, limitação de taxa, novas tentativas, proxies e cabeçalhos personalizados. Extraia dados de qualquer site usando CSS ou regex.
Playwright
Playwright é uma biblioteca Node.js para automatizar navegadores da web, como Chromium, Firefox e WebKit, fornecendo uma API de alto nível para controlar aplicativos da web.
Node Crawler
O Node Crawler é uma poderosa biblioteca de rastreamento e raspagem da Web para Node.js que oferece suporte a recursos como proxy, limitação de taxa e integração com jQuery.
Ruia
Ruia é uma microestrutura de raspagem da web em Python assíncrona com uma API simples, extensibilidade e suporte para vários tipos de conteúdo da web.
AutoScraper
O AutoScraper é uma biblioteca Python que automatiza a raspagem da web usando aprendizado supervisionado para extrair dados de sites com eficiência e precisão.
StormCrawler
StormCrawler é uma estrutura de rastreamento da web de código aberto construída no Apache Storm para rastreamento da web e extração de dados escalonáveis, personalizáveis e distribuídos.
MechanicalSoup
MechanicalSoup é uma biblioteca Python para automatizar a navegação na web e o preenchimento de formulários, construída sobre as bibliotecas Requests e Beautiful Soup.
Beautiful Soup
Beautiful Soup é uma biblioteca Python para analisar documentos HTML e XML, fornecendo uma interface fácil de usar para navegar em árvores de análise.
Kimurai
Kimurai é uma estrutura de raspagem da web leve e flexível para Ruby, com uma sintaxe simples, ótimo desempenho e suporte integrado para vários formatos de armazenamento.
Jaunt
Jaunt é uma estrutura de automação e raspagem da web baseada em Java que fornece uma API simples, flexível e robusta para extrair dados de páginas da web.
Cheerio
Cheerio é uma ótima opção para web scraping em JavaScript por causa de sua simplicidade, velocidade e flexibilidade, bem como sua compatibilidade com Node.js e comunidade ativa.
Go Colly
Go Colly é uma estrutura de raspagem da web baseada em Go que fornece uma maneira simples e eficiente de extrair dados de sites, com suporte para solicitações paralelas, sites dinâmicos e personalização.
Puppeteer
Puppeteer é uma biblioteca Node.js desenvolvida pelo Google, que fornece uma API de alto nível para controlar um navegador Chrome sem cabeça. Ele permite que os desenvolvedores automatizem tarefas, raspem dados e testem aplicativos da web.
Apify
O Apify é uma poderosa plataforma de extração e automação da web que fornece aos usuários um conjunto abrangente de ferramentas para extrair dados de sites, automatizar fluxos de trabalho e implantar rastreadores da web na nuvem.
Scrapy
Scrapy é uma estrutura de rastreamento da web. Web scraping, mineração de dados, processamento de informações e estrutura de teste automatizada.
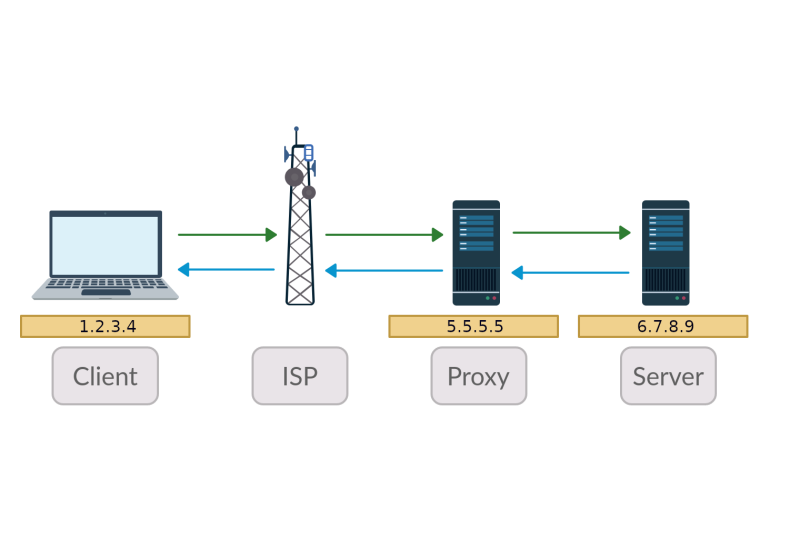
O que é Proxy
Por que você precisa usar proxy e como ele funciona. Como o proxy pode ajudá-lo a permanecer mais anônimo e abrir sites bloqueados.
Proxy para Web Scraping
Uma boa solução de proxy para Web Scraping deve fornecer um mecanismo de rotação de proxy e ser facilmente conectável a estruturas de raspagem.