☰
×
网页抓取
网页浏览
jsoup
Jsoup 是一个用于解析和操作 HTML 文档的 Java 库。 它提供了一个易于使用的 API,用于从 HTML 中提取和修改数据。
Norconex
Norconex Web Crawler 是一个用于网络爬取和数据提取的开源工具,用于从网站收集数据以进行业务分析和洞察。
Guzzle
Guzzle 是一个 PHP HTTP 客户端库,可简化向网站和 API 发送请求,为网络抓取任务提供易于使用的功能。
Apache Nutch
Apache Nutch 是一种开源网络爬虫和搜索引擎软件,可以对大量网络内容进行爬网和索引。
Ayakashi.io
Ayakashi.io 是一个基于 Node.js 的网络抓取框架,具有无头浏览器自动化、动态网页和单页应用程序抓取功能。
Crawlee
Crawlee 允许您抓取和抓取网站。 并发、速率限制、重试、代理和自定义标头。 使用 CSS 或正则表达式从任何网站提取数据。
Playwright
Playwright 是一个 Node.js 库,用于自动化 Web 浏览器(例如 Chromium、Firefox 和 WebKit),提供高级 API 来控制 Web 应用程序。
Node Crawler
Node Crawler 是一个强大的 Node.js 网络爬虫和抓取库,支持代理、速率限制和 jQuery 集成等功能。
Ruia
Ruia 是一个异步 Python 网络抓取微框架,具有简单的 API、可扩展性和对各种类型的网络内容的支持。
AutoScraper
AutoScraper 是一个 Python 库,它通过使用监督学习从网站中高效准确地提取数据来自动进行网页抓取。
StormCrawler
StormCrawler 是一个基于 Apache Storm 构建的开源网络爬虫框架,用于可扩展、可定制和分布式的网络爬虫和数据提取。
MechanicalSoup
MechanicalSoup 是一个用于自动浏览网页和填写表单的 Python 库,它建立在 Requests 和 Beautiful Soup 库之上。
Beautiful Soup
Beautiful Soup 是一个用于解析 HTML 和 XML 文档的 Python 库,提供了一个易于使用的界面来导航解析树。
Kimurai
Kimurai 是一个灵活且轻量级的 Ruby Web 抓取框架,具有简单的语法、出色的性能和对多种存储格式的内置支持。
Jaunt
Jaunt 是一个基于 Java 的网络抓取和自动化框架,它提供了一个简单、灵活和健壮的 API,用于从网页中提取数据。
Cheerio
Cheerio 是 JavaScript 网页抓取的绝佳选择,因为它简单、快速、灵活,并且与 Node.js 和活跃的社区兼容。
Go Colly
Go Colly 是一个基于 Go 的网络抓取框架,它提供了一种简单高效的方式来从网站中提取数据,支持并行请求、动态网站和自定义。
Puppeteer
Puppeteer 是 Google 开发的一个 Node.js 库,它提供了一个用于控制无头 Chrome 浏览器的高级 API。 它使开发人员能够自动执行任务、抓取数据、测试 Web 应用程序。
Apify
Apify 是一个强大的网络抓取和自动化平台,为用户提供了一套全面的工具,用于从网站提取数据、自动化工作流程以及在云中部署网络爬虫。
Scrapy
Scrapy 是一个网络爬虫框架。 Web 抓取、数据挖掘、信息处理和自动化测试框架。
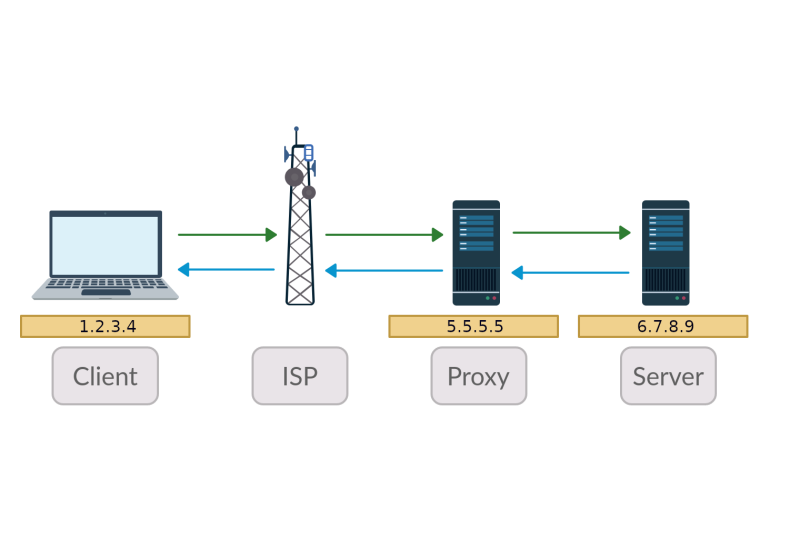
什么是代理
为什么需要使用代理及其工作原理。 代理如何帮助您保持匿名并打开被阻止的站点。
网页抓取代理
一个好的 Web Scraping 代理解决方案应该提供代理轮换机制,并且应该很容易插入到抓取框架中。