☰
×
Scraping
Browsing
jsoup
Jsoup is a Java library used for parsing and manipulating HTML documents. It provides an easy-to-use API for extracting and modifying data from HTML.
Norconex
Norconex Web Crawler is an open-source tool for web crawling and data extraction, used to collect data from websites for business analysis and insights.
Guzzle
Guzzle is a PHP HTTP client library that simplifies sending requests to websites and APIs, providing easy-to-use features for web scraping tasks.
Apache Nutch
Apache Nutch is an open-source web crawler and search engine software that enables the crawling and indexing of large volumes of web content.
Ayakashi.io
Ayakashi.io is a web scraping framework built on Node.js, featuring a headless browser automation, dynamic web pages and Single Page Applications scraping.
Crawlee
Crawlee allows you to scrape and crawl websites. Concurrency, rate limiting, retries, proxies, and custom headers. Extract data from any website using CSS or regex.
Playwright
Playwright is a Node.js library for automating web browsers such as Chromium, Firefox, and WebKit, providing a high-level API to control web apps.
Node Crawler
Node Crawler is a powerful web crawling and scraping library for Node.js that supports features like proxying, rate limiting, and jQuery integration.
Ruia
Ruia is an asynchronous Python web scraping micro-framework with a simple API, extensibility, and support for various types of web content.
AutoScraper
AutoScraper is a Python library that automates web scraping by using supervised learning to extract data from websites efficiently and accurately.
StormCrawler
StormCrawler is an open-source web crawling framework built on Apache Storm for scalable, customizable, and distributed web crawling and data extraction.
MechanicalSoup
MechanicalSoup is a Python library for automating web browsing and form filling, built on top of Requests and Beautiful Soup libraries.
Beautiful Soup
Beautiful Soup is a Python library for parsing HTML and XML documents, providing an easy-to-use interface for navigating parse trees.
Kimurai
Kimurai is a flexible and lightweight web scraping framework for Ruby, with a simple syntax, great performance, and built-in support for multiple storage formats.
Jaunt
Jaunt is a Java-based web scraping and automation framework that provides a simple, flexible, and robust API for extracting data from web pages.
Cheerio
Cheerio is a great choice for web scraping in JavaScript because of its simplicity, speed, and flexibility, as well as its compatibility with Node.js and active community.
Go Colly
Go Colly is a Go-based web scraping framework that provides a simple and efficient way to extract data from websites, with support for parallel requests, dynamic websites, and customization.
Puppeteer
Puppeteer is a Node.js library developed by Google, which provides a high-level API for controlling a headless Chrome browser. It enables developers to automate tasks, scrape data, test web applications.
Apify
Apify is a powerful web scraping and automation platform that provides users with a comprehensive suite of tools for extracting data from websites, automating workflows, and deploying web crawlers in the cloud.
Scrapy
Scrapy is a web crawling framework. Web scraping, data mining, information processing, and automated testing framework.
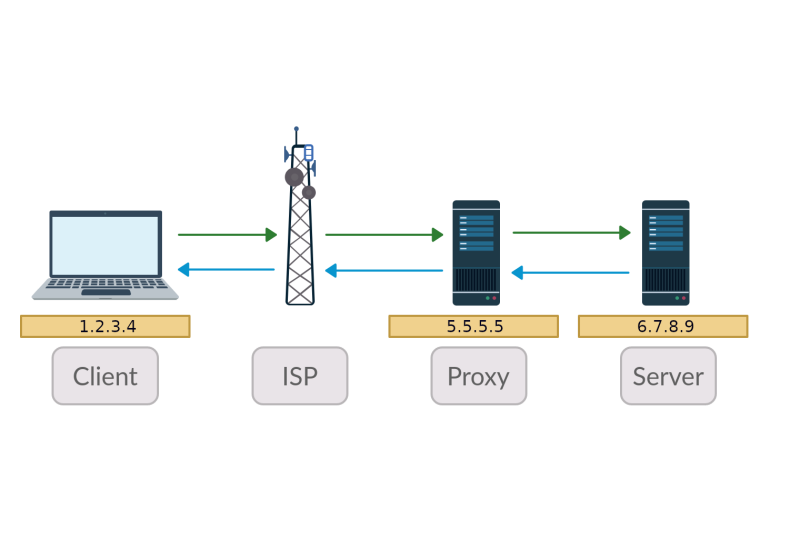
What is Proxy
Why you need to use proxy and how it works. How proxy can help you to stay more anonymous and open blocked sites.
Proxy for Web Scraping
A good proxy solution for Web Scraping should provide a proxy rotation mechanism and should be easily pluggable into scraping frameworks.